Extracting addresses from OpenStreetMaps

Why?
Because there is no worldwide quality source for addresses!
Really, that's no joke. There are many commercial providers for "industrialized countries" of variable quality/pricing but worldwide coverage is lacking, the data formats are diverse and the license terms provider specific.
There are also some open source projects related to addresses though, each with their gochas. Two of these projects are mentioned in the last section "Honorable Mentions" at the end of this article, along with their drawbacks.
This project is born in order to provide quality addresses with worldwide coverage under an open license, by directly extracting addresses from the raw data dumps of OpenStreetMap.
Birth of OpenStreetData.org
How does the it look like? Here is a screenshot, but if you prefer, check out the website directly.

It is divided into two parts: extracts and addresses. Another "points of interest" was planned, but not further developed due to lack of time.
Country dumps
Country extracts are provided in two formats:
PBF, the native OpenStreetMap binary format. This format is very compact and many tools can handle it efficiently. Nevertheless, it is not always very practical to handle due to its low-level nature. It's basically a huge list of points with IDs, lines that reference these IDs and relations that reference the lines.
GeoJson sequences. It's a text file where each line is a "feature": a JSON object with arbitrary properties and a geometry with coordinates. Although the file size is typically larger and the processing sometimes slower, it offers other benefits. The JSON format is universal, the line-based sequence makes it straightforward to filter it with grep-like tools and the geometry can be parsed directly without requiring to go through the whole file.
Note though that both formats are not 100% equivalent. During the conversion process, some choices were required to be made. In particular, in the original PBF a "closed line" (where the last point is the same as the first) could be interpreted as a line or as an area either way. There is no clear-cut indication whether it's a "line" happening to turn in a circle, like a roundabout, or a polygonal "area", like a building outline. This led to "closed lines" being interpreted as lines or polygons based on a lot of hand-picked feature properties. For example, if building=... was part of the properties, it was considered a polygon, except if an area=false tag was also present, and so on.
Administrative areas
Despite not being shown on the site, extracting precise boundaries of a country's provinces, regions, counties, cities, suburbs and so on was the first crucial step. How a country is subdivided into smaller areas varies greatly from country to country and is abstracted under the name "administrative areas" of various levels.
This step is crucial because of the way addresses are extracted. Streets and houses were extracted using "spatial joins" with the administrative areas. Their coordinates were used to determine which administrative areas (city, county, province...) they belong to, as well as the postal code ...if postal code areas are defined in the country.
Currently, the reason of missing (or wrong) addresses for some countries are improper mapping of the administrative areas.
Streets
Here is an example of the "streets" for Austria:
| suburb | country | state | province | city | postal_code | street_name |
| Abtsdorf | AT | Oberösterreich | Bezirk Vöcklabruck | Attersee am Attersee | 4864 | Abtsdorf |
| Abtsdorf | AT | Oberösterreich | Bezirk Vöcklabruck | Attersee am Attersee | 4864 | Altenberg |
| Abtsdorf | AT | Oberösterreich | Bezirk Vöcklabruck | Attersee am Attersee | 4864 | Attergauer Landesstraße |
| Abtsdorf | AT | Oberösterreich | Bezirk Vöcklabruck | Attersee am Attersee | 4864 | Attersee |
| Abtsdorf | AT | Oberösterreich | Bezirk Vöcklabruck | Attersee am Attersee | 4864 | Atterseestraße |
| ... | ... | ... | ... | ... | ... | ... |
| AT | Vorarlberg | Bezirk Feldkirch | Marktgemeinde Rankweil | 6830 | Wüstenrotgasse | |
| AT | Vorarlberg | Bezirk Feldkirch | Marktgemeinde Rankweil | 6830 | Zehentstraße | |
| AT | Vorarlberg | Bezirk Feldkirch | Marktgemeinde Rankweil | 6830 | Zieglerweg | |
| AT | Vorarlberg | Bezirk Feldkirch | Marktgemeinde Rankweil | 6830 | Zunftgasse | |
| AT | Vorarlberg | Bezirk Feldkirch | Marktgemeinde Rankweil | 6830 | Übersaxner Straße |
168769 rows × 7 columns
It extracted all streets having a name from the raw data and determined the administrative areas and postal code it belongs according to their centroid. As such, it is a slightly simplified streets list. If a street might cross multiple cities or postal codes for example, it will solely be listed in the "main one" (according to its center). For more precise addresses, see below.
Note that "suburb" may be empty depending on the size of the city. This is normal since not all cities are further divided into suburbs.
Houses
Houses is a dataset listing each house (anything with a house number) individually, including its coordinates and the administrative areas it lies within.
Addresses
In this case, the houses are "merged" into streets with house numbers. Unlike the "streets" approach, it results in a more fine-grained dataset.
it includes only streets with at least a single house (number)
it differentiates between street sections with house number ranges belonging to different administrative areas or postal codes
it differentiates between different sides of the street (with odd/even house numbers) belonging to different administrative areas or postal codes
it has boundaries
Here is an example of such an address file for Austria.
| postal_code | city | street | x_min | x_max | y_min | y_max | house_min | house_max | house_odd | house_even | |
| 0 | 1010 | Vienna | Weihburggasse | 16.375769 | 16.375769 | 48.205242 | 48.205242 | 26 | 26 | True | True |
| 1 | 1010 | Wien | Abraham-a-Sancta-Clara-Gasse | 16.362970 | 16.363213 | 48.209789 | 48.209910 | 1 | 2 | True | True |
| 2 | 1010 | Wien | Akademiestraße | 16.370855 | 16.372425 | 48.200877 | 48.203575 | 1 | 13 | True | True |
| 3 | 1010 | Wien | Albertinaplatz | 16.368138 | 16.369344 | 48.204084 | 48.204750 | 1 | 3 | True | True |
| 4 | 1010 | Wien | Alte Walfischgasse | 16.371740 | 16.371740 | 48.203559 | 48.203559 | 9 | 9 | True | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 147137 | 9991 | Gemeinde Dölsach | Waidachweg | 12.825955 | 12.827117 | 46.830659 | 46.831055 | 4 | 9 | True | True |
| 147138 | 9991 | Gemeinde Dölsach | Wenzl PLatz | 12.841072 | 12.841634 | 46.826521 | 46.826902 | 1 | 3 | True | True |
| 147139 | 9992 | Gemeinde Iselsberg-Stronach | Großglockner Straße | 12.841043 | 12.858008 | 46.833271 | 46.854501 | 1 | 206 | True | True |
| 147140 | 9992 | Gemeinde Iselsberg-Stronach | Iselsberg | 12.835091 | 12.855994 | 46.833822 | 46.846260 | 5 | 212 | True | True |
| 147141 | 9992 | Gemeinde Iselsberg-Stronach | Stronach | 12.849133 | 12.858230 | 46.826562 | 46.833270 | 2 | 63 | True | True |
146322 rows × 11 columns
It may not be perfect, for example, the first line with a misinterpreted city name is quite mysterious.
Challenges
"Big Data"
Dealing with large data is challenging. It's not thousands of points, it's not millions, it's many billions of points, lines, polygons and relations.
Seems like a detail? Well, for example, you cannot even load the planet's data at once in memory. It's simply too big.
You cannot just "do as you please" with inefficient code. Every line of code, every operation, must be crafted with care, well thought out, and fine-tuned to keep processing time and memory to a minimum.
As an example, just for processing the data of a single country, even 32Gb RAM is not enough for larger countries and it takes many hours with the current code, despite best efforts.
Producing precise country extracts
There are sites like geofabrik.de providing country extracts to download. However, they turned out to be not precise enough for me. They use "simplified country border polygons" that are "cutting corners" and therefore missing addresses in areas near the borders. So I had to "split the planet" myself.
To do so, the first step was to extract exact country boundaries. Interestingly, these might change over time. Usually, it's minor modifications like slightly adjusting the border or correcting mistakes. But sometimes the border might move a bit more in "unstable" parts of the world. The point here is that these borders are not "definitive" but evolve slightly over time.
The next step is splitting the world into country extracts. Here again, it cannot be naively done in a single step. Doing so, even 256Gb RAM would not suffice to split at once. So the splitting must be done in multiple steps: first in continents, then in regions, then in countries so that it fits in a "reasonable" amount of memory.
And cutting whole continents with a super precise boundary constituted from millions of points is not efficient either. On the other hand, computing the total bounds of the continent is pointless too. For example, the outer bounds of just France would cover almost the whole world since it possesses many islands around the world as part of its territory. You get the point, some extra work must be done to simplify the geometry without losing stuff but without including too much either.
Then, there are ways or area relations that cross boundaries. Some things from the raw data are not always clear whether it's a "closed line" or an "area", and so on. It's full of technical details which make even producing what look like simple "country extracts" challenging.
Heterogenous data
The OpenStreetMap raw data is not a homogenous clearly defined dataset. It is a huge amount of points, lines and relations, each with completely arbitrary properties. For example, a statue might be a point with metadata indicating when it was built, and from whom, along with some tourist guide number. Depending on where you look on the map, you may also notice different habits of mappers using a diversified arsenal of "tags" to describe things and the community as a whole has different opinions on how to do things, for example with addresses, which often have local flavours.
If you dig into the raw data of OpenStreetMap, you will find interesting things. For example, you will find tags like addr:street=... and addr:city=... which sounds promising. These are also very simple (and quick) to extract since it's attached directly to the data. Great right? Well, it would be this data was complete but it is far from. Depending on the country you are looking at, it might be mostly widespread or barely used. Even if it's there, the coverage and the content are usually quite fuzzy. For example, the street might be named "Wall Street" on one building while another building uses "Wall St.". Likewise, the city in one building may be "N.Y. City" while another uses "New York". Postcodes may also be written in individual houses, but not match the postal boundary accurately, etc. This makes processing these tags directly error-prone. It's better than nothing but there are ways to make it better.
Namely what we did. Spatial joins of houses/streets points into administrative/postal areas in order to extract the most information possible. If those areas are not mapped, a fallback to the tags is used, but only as "fallback" since they are usually not that precise.
Manual labor
Doing this is quite some work. It's not just running a process and be done with it. It's craftsmanship where you change a few lines of code and manually inspect the results. Just checking if more streets/houses/addresses are produced is not sufficient either. It might be that the output is of worse quality because street names are duplicated or listed in the wrong "areas" or some other data mistakes. It might also be that the "couple of lines change" works perfectly for one country but breaks in another because of local differences, like for example the presence or absence of postal codes.
Sometimes, you also see odd things in the data. When this happens you usually spend some time to investigate "why" it is so. Is it the raw map data that is strange? Is it some situation you did not think of? Is there a bug in the code? Is some third-party library not working as expected?... It's really full of weird things, from buildings on the map having mistakenly used "national boundaries" tags to sudden performance drops in third-party libraries when calling a certain function.
Addresses are crazy
Below, I will illustrate how addresses are crazy. It's not something that is homogenous worldwide. It's full of regional quirks.
Is it a country or not?
You may think that something as basic as countries and boundaries is clear-cut. But it is not. Take Kosovo for example.

For half of the world (marked in red), Kosovo constitutes a province of Serbia, while for the other half of the world (marked in blue) Kosovo is recognized as an independent country.
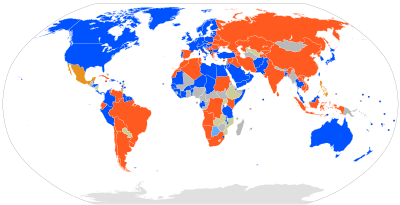
...and that's not unique to Kosovo. There are plenty of regions in the world where territory is disputed, where border shift with local wars and where sovereignty depends on who you ask.
What stance do I take here? I simply use the list of countries as defined by the united nations, defined by their country codes ISO 3166-1. It might not be ideal, but it is pragmatic.
A city with many borders
On a small scale level, borders can be crazy too. For example, check out the little town of Baarle-Nassau, located in the south of the Netherlands, near the Belgium border.

This town contains 22 small exclaves of the Belgian town Baarle-Hertog, some of which contain counter-exclaves of Nassau. The borders cross streets in the middle, sometimes multiple times and a single house might have a Belgium address on one side and a Netherlands address on the other. As you see, extracting addresses can quickly become challenging. ;)
A city center without street names
Not all addresses are based on "streets". Take a look a Mannheim for example. There, the city center is divided like a big grid.

There, each "block" has an identifier, like "C3" while the streets are unnamed. Likewise, house number does not belong to a "street" but to a block. In other words, your address might be "C3, 17" if you live in building 17 of block "C3".
Fancy house numbers
Do you want to use regexes to filter valid house numbers? Well, that might not really work out. For example, the following image is a valid Vietnamese house number, near the coasts of Ho Chi Minh city.
The world is full of surprises. Also regarding addresses, it's full of diversity and local quirks and I believe there is nothing that does not exist.
Honorable mentions
There are also two noticeable open source projects trying to bring addresses to the public domain.
This is probably the most famous one. It works by running various "scraping scripts" against various "raw data sources". The result of this approach has few drawbacks though, directly related to its approach.
the licensing is problematic. Basically, it says "use this data according to the license from the data source" ...which is not obvious, since the original issue is not directly linked, often in native language and the licensing terms makes the usage of this data questionable.
the coverage is lacking
the scraping sometimes breaks or is outdated because of changes in the raw source
despite being "open", some things are obfuscated and make reproducing or direct downloads difficult

Despite less known, this is IMHO a better source of addresses. It is based on addresses extraction from OpenStreetMap and therefore has worldwide coverage and a homogenous license: the "ODbL - Open Database License".
The only drawback it has IMHO is:
the lack of postal codes
the
admin_levelmapping not ideal
The lack of postal codes may seem like a detail, but it is crucial for addresses. Without it, addresses are simply incomplete. Since this project is open source, I also tried to improve it by adding postal code (see issue) but it turned out too be too difficult/challenging for me. Mostly because I am unfamiliar with PostGIS. The code however, is of quality. This lead me to the current project.
The second issue is more subtle, and leads to missing addresses in some countries because administrative boundaries are not properly mapped. Also, the code is not suited for experimentation and from my understanding, there were ways to "get more" out of the raw OpenStreetMap data dumps than how they did it.